





概述
从技术层面,敏捷开关是 feature flags 技术实现工具与管理平台,像海外独角兽 launchdarkly.com 所示, Feature flags 技术和 Feature 管理平台,可以让软件的发布更快、更安全。而量化"发布更快、更安全",我们可以从DevOps性能去分析和量化。这篇文章,我们使用谷歌团队历经7年,根据来自32000名专业人士的数据,制定的DORA(DevOps Research and Assessment)指标,来分析 feature flags 系统如何提升DevOps性能,量化"更快、更安全"。

DORA主要使用四个指标来测量软件交付性能:
- Deployment frequency (部署、发布频率),即团队把代码上传并部署上线或发布给用户的频率,如2周1次、1周2次、1天10次等。
- Lead time for changes (推送代码到交付的时间),即从推送代码到某个分支开始,到将代码对应的新特性发布到生产环境的时间。
- Time to restore service (事故发生到修复的时间) ,即从发现服务异常(事故、BUG等)到解决问题并重新恢复服务的时间。
- Change failure rate (变更失败率),即指对服务进行的变更中,导致补救、事故、回滚或失败部署的百分比。
关于四个指标的一些容易让人误会的理解的解释可以阅读油管中的视频
https://www.youtube.com/watch?v=YOvEIFLWz3I
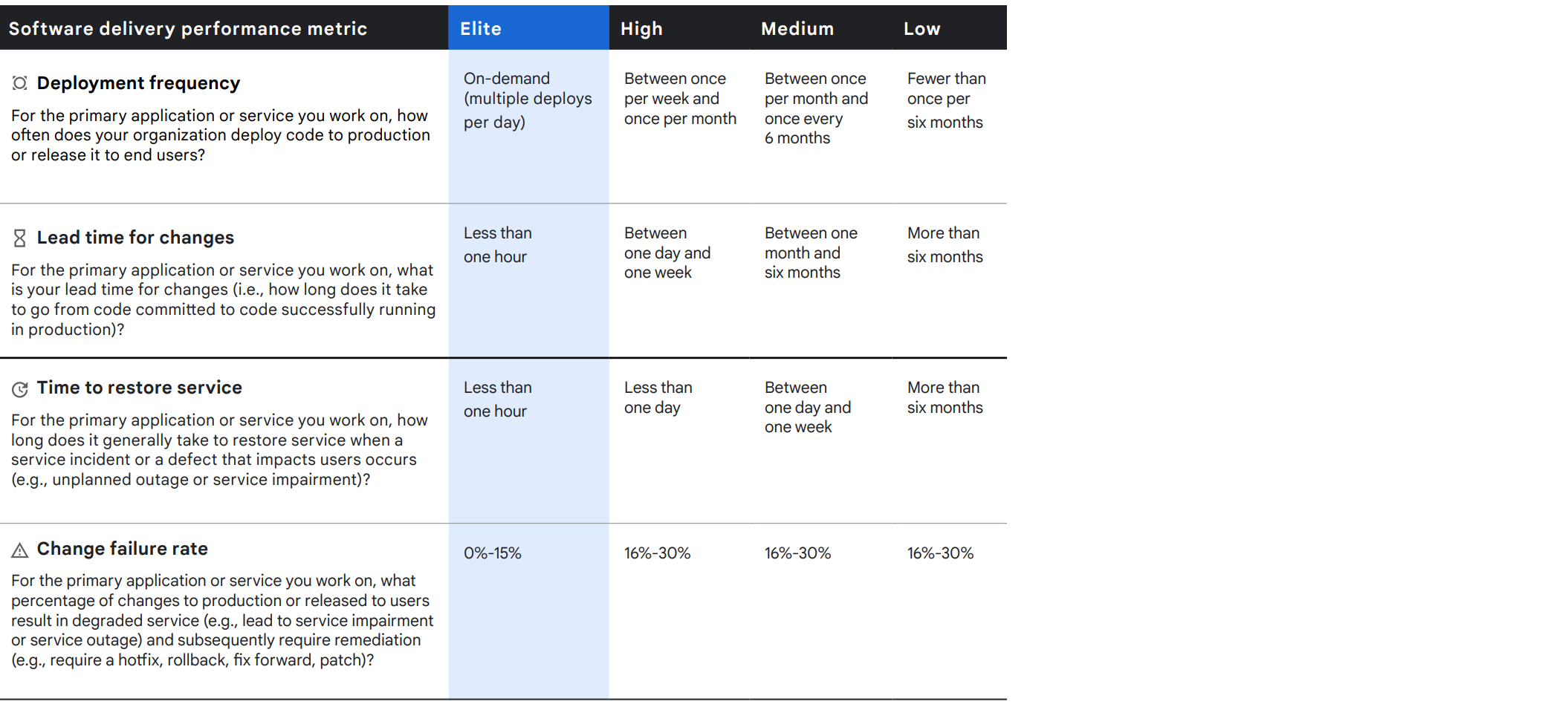
如上图所示(来自DORA报告 state-of-devops-2021),DORA对指标测试定义了Elit/High/Medium/Low四个性能级别,来判断团队的研发和交付性能处在何种水准。下面将具体讲述Feature flags是如何具体提升团队在每个指标上的能力,以及现有相关产品的客户反馈与实际效果。

Deployment Frequency (部署、发布频率)
部署和发布频率的提高,可以支持软件以更小的力度做变更,出错概率更低,调整策略更及时、灵活,产品和企业试错机会更多,获得试错反馈的时间就会更提前,迭代速度更快。
对于一些小的产品和团队,一天发布多次是容易实现的,而对于一个较为成熟的企业实现高频交付,就相对困难很多,而这也是优秀团队克服的问题。使用Feature Management平台,可以帮助克服相关问题。
在代码中集成Feature Flags来控制Feature的运行与否,当Feature Flag处于激活状态时功能运行,否则不运行。因为如此,所以我们可以在任何时间状态下将一个Feature branch合并到主分支,并部署到上线(即使是没有完成的功能)。
上线后,由Feature Flag控制功能的发布。我们可以把准备好的功能用渐进式方式发布给用户,把一些测试阶段(或开发阶段的)功能单独的发布给内部人员和指定客户。这种"先上线、再发布"的模式,避免了因为代码合并混乱、排期审核过长、担忧BUG等问题,影响研发与交付性能上的不足。
目前国际公开的使用Feature Management平台的客户都已实现 DORA 的Elit Performer的标准,相对于不使用Feature Flags提高了9倍的部署或发布频率。
Lead time for changes(推送代码到交付的时间)
推送代码(Commit)到交付之间,往往需要代码合并、审核、等到排期约定时间一同发布。这样做的原因,往往是考虑到合并混乱、担忧BUG、协同等待、资源匹配等问题。尤其是一个由多服务共同组成的复杂系统,不仅要考虑到应用程序自身的特性更新,还要考虑到配套数据相关、硬件资源相关的版本匹配的一系列问题。
使用Feature Flags后,功能特性被Flag的标记(或包裹),即是对一个应用程序,也是对整个系统的控制与协调(即一个特性的更新是以Flag做中心版本控制)。一个新的commit到部署上线的过程,通过Flag控制,使合并混乱、BUG、协同等待等问题的风险降到非常低。即使有问题出现,也可以通过控制Flag的方式快速秒级回退至之前稳定的版本。
所以,我们可以在推送代码(Commit)后,更大胆的合并、触发CICD,将新的功能特性部署上线,然后在生产环境做一些早期测试。根据国际公开的信息,一个好的Feature Management 平台可以**降低70%以上**的从推送代码到交付的时间。
PS:70%和9倍并不矛盾,9倍可以简单理解为每天去触发CICD的频率(且可能是多个不同功能模块),70%可以理解为对一个功能模块的修改到上线提效。Feature flags 技术使其可以无畏地、并行地推送、合并、发布多个功能特性。
Time to restore service(事故发生到修复的时间)
从事故发生到修复,涉及到诸多环节,如定位事故原因、切换到一个旧版可用(或备用)服务、修复系统、重新恢复服务等。每个环节都有可能占据一定的时间。而Feature Management平台往往可以在切换旧版(或备用)服务、重新恢复服务两个环节起到立竿见影的作用,并且对修复系统和定位事故原因做出辅助作用。
因为Feature被Flag包裹和控制,所以只需要使用平台中的UI工具,就可以快速的切换系统至可用状态。有些复杂的场景,可能需要做不同功能特性的Feature Flags版本联调。而这个联调的过程,也是快速定位问题来源的过程(尤其是很多问题并不能被单一服务的相关技术人员发现)。
犹如上面第1、2条讲述,当一个问题被修复、重新上线发布时,其可高频交付、短暂的推送至交付时间,也将大大的增加事故发生到修复的效率。使用好的 Feature Management 平台的客户中,据部分平台统计,有超过四成客户**达到Elit标准**(即平均恢复时间小于1小时),超九成客户达到High及以上标准。
PS:尤其是事故的出现只影响了一小部分用户(或设备),小范围的控制、回退也常常会给整个系统的修复畅通带来巨大的贡献。这也是一个好的Feature Management平台的优秀特性。
Change failure rate(变更失败率)
变更失败率(CFR)是指导致停机、服务下降或回滚的发布的百分比,它可以告诉你一个团队在实施软件更新方面的效率如何。
变更失败率是一个特别有价值的指标,因为它可以防止一个团队被他们遇到的失败总数所误导。虽然那些更新慢的团队会看到更少的失败,但这并不代表他们在部署更新更成功。那些遵循持续交付实践的团队可能会看到更多的失败,但如果CFR很低,这些团队就会有优势,因为他们的部署速度更快、总体成功率更高。这个比率也可以对价值流产生重大影响。它可以表明有多少时间是用于补救问题而不是开发新项目。因为高、中、低绩效者都在同一范围内,所以最好是根据团队和特定业务来设定目标,而不是与其他组织进行比较。
正如上文所示,这些被更新的功能特性并未直接发布至用户,所以他几乎不可能会产生失败的效果。相反,一旦功能被逐步地发布,虽然会有失败的几率,但爆炸半径可以非常小。我们可以通过Feature Management平台精准定位问题用户,配合细粒度秒级回退,将风险抑制到最低,并可以让工程师在压力较小的情况下更快的修复。
据统计,使用Feature flags系统的用户,超七成以上为Elit级别的“变更失败率”,而长期使用优秀Feature Management平台的用户,超**九成以上为Elit级别的“变更失败率”,即变更失败率在0-15%之间**。
重要的幸福时刻
根据谷歌历年的报告,欧美越来越多的企业的DORA指标得到了改善。尤其是随着 Feature flags 工具和平台在欧美的兴起,企业交付软件的能力又一次得到大幅度提升。而欧美定义的"软件交付"能力的提高,直接提升的实际上是企业的是迭代速度、试错的成功概率。在企业拥有了DevOps理念后,非常有必要引进Feature Flags系统实现再一次质的降本增效的突破。
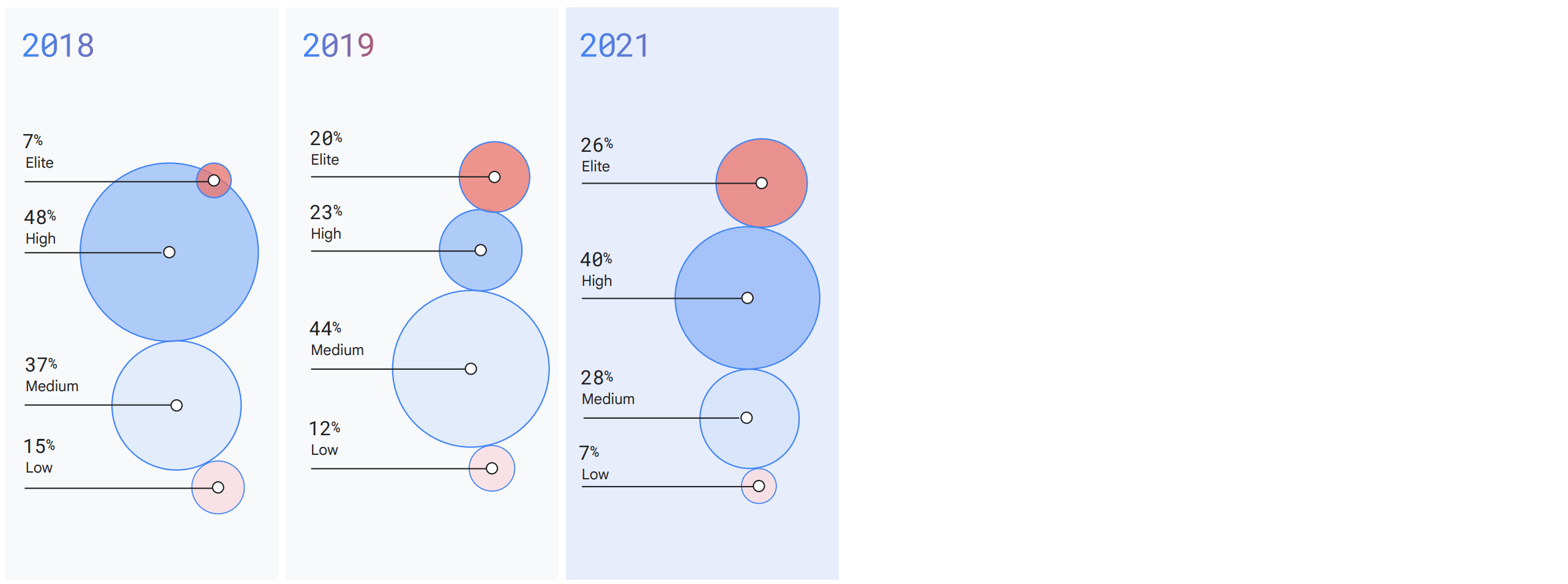
在launchdarkly.com携带其竞品引领欧美数字化升华的时候,中国企业和团队也需要同样的工具来快速提升竞争力。很幸运的是,2021年末,原微软全球执行副总裁陆奇博士的“奇绩创坛”基金投资了项目"敏捷开关 https://featureflag.co",希望feature flags系统也可以在中国快速发展,助力软件行业腾飞。




请留下具体问题或建议